 Escuchar
Escuchar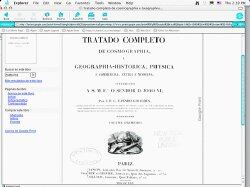
Google lanzó ayer la primera fase del proyecto de digitalizar millones de libros para que puedan ser leídos a través de Internet.
En la versión inicial de Google Print (print.google.com), los usuarios pueden buscar todos los libros de texto "escaneados " y ver algo similar a una tarjeta de catálogo con extractos contextualizados de sus términos de búsqueda.
"Los usuarios solo pueden leer más de cualquier libro que encuentren, si el libro no tiene derechos de autor reservados o si el editor dio permiso explícito de mostrar páginas enteras o una porción limitada del libro", indicó la empresa.
Biblioteca en línea. Pese a los reclamos de la industria editorial estadounidense, que intenta desbaratar la idea de Google de copiar los libros con derecho de autor, la compañía y sus bibliotecas asociadas pusieron su primera colección de trabajos en el dominio público.
Las universidades de Harvard, Stanford, Michigan y la Biblioteca Pública de Nueva York contribuyeron con libros históricos sobre la guerra civil de Estados Unidos, documentos gubernamentales, los escritos de Henry James y otros libros para el programa.
Además de buscar y leer el contenido de las páginas, los usuarios pueden guardar las imágenes.
Otro de los vínculos permite buscar el documento en alguna de las librerías en línea, aún ediciones antiguas. Por ejemplo, cada uno de los 10 tomos de la impresión de 1907 de la Colección de Documentos para la Historia de Costa Rica, compilados por León Fernández Bonilla.
Con futuro. El material ofrecido representa "apenas una pequeña fracción de la información que estará eventualmente disponible gracias a Google Print", dijo un portavoz.
La empresa no indicó cómo manejará el tema de los derechos de autor si ofrece en Internet versiones de libros más actuales.
Desde que Google hizo su anuncio, Yahoo y Microsoft divulgaron planes similares, pero aclarando que no violarían derechos de autor registrados.
